• Artículo
Análisis del reconocimiento facial continuo en React para proteger documentos confidenciales

El reconocimiento facial en aplicaciones web suele asociarse con autenticación, reemplazar contraseñas por tu cara. Pero hay un caso de uso menos explorado y más exigente técnicamente: vigilancia continua de privacidad. No verificar quién eres una vez, sino monitorear constantemente quién está frente a la pantalla mientras documentos sensibles están visibles.
En 2023, trabajé en un proyecto donde el requerimiento era exactamente ese. El producto era un SaaS que originalmente funcionaba como aplicación mobile nativa, y el equipo estaba migrándolo a una app híbrida con ReactJS para unificar el código entre mobile y web. La aplicación mostraba documentos confidenciales, y el cliente necesitaba garantizar que solo el usuario autorizado pudiera verlos. Si otra persona aparecía frente a la cámara, un compañero de trabajo mirando por encima del hombro, alguien pasando detrás, la pantalla debía bloquearse de inmediato. Y solo desbloquearse automáticamente cuando la cámara detectara únicamente el rostro del usuario autorizado.
La migración a React añadía una restricción importante: la solución de reconocimiento facial tenía que funcionar tanto en el navegador web como dentro de un webview en mobile, con el mismo código base. Eso descartaba SDKs nativos de iOS/Android y nos empujaba hacia librerías JavaScript que corrieran en el contexto del browser.
Este artículo documenta la arquitectura que diseñamos, las decisiones técnicas que tomamos, lo que funcionó, lo que no, y qué cambiaría si tuviera que resolverlo hoy.
La arquitectura: detección en el cliente, reconocimiento en el servidor
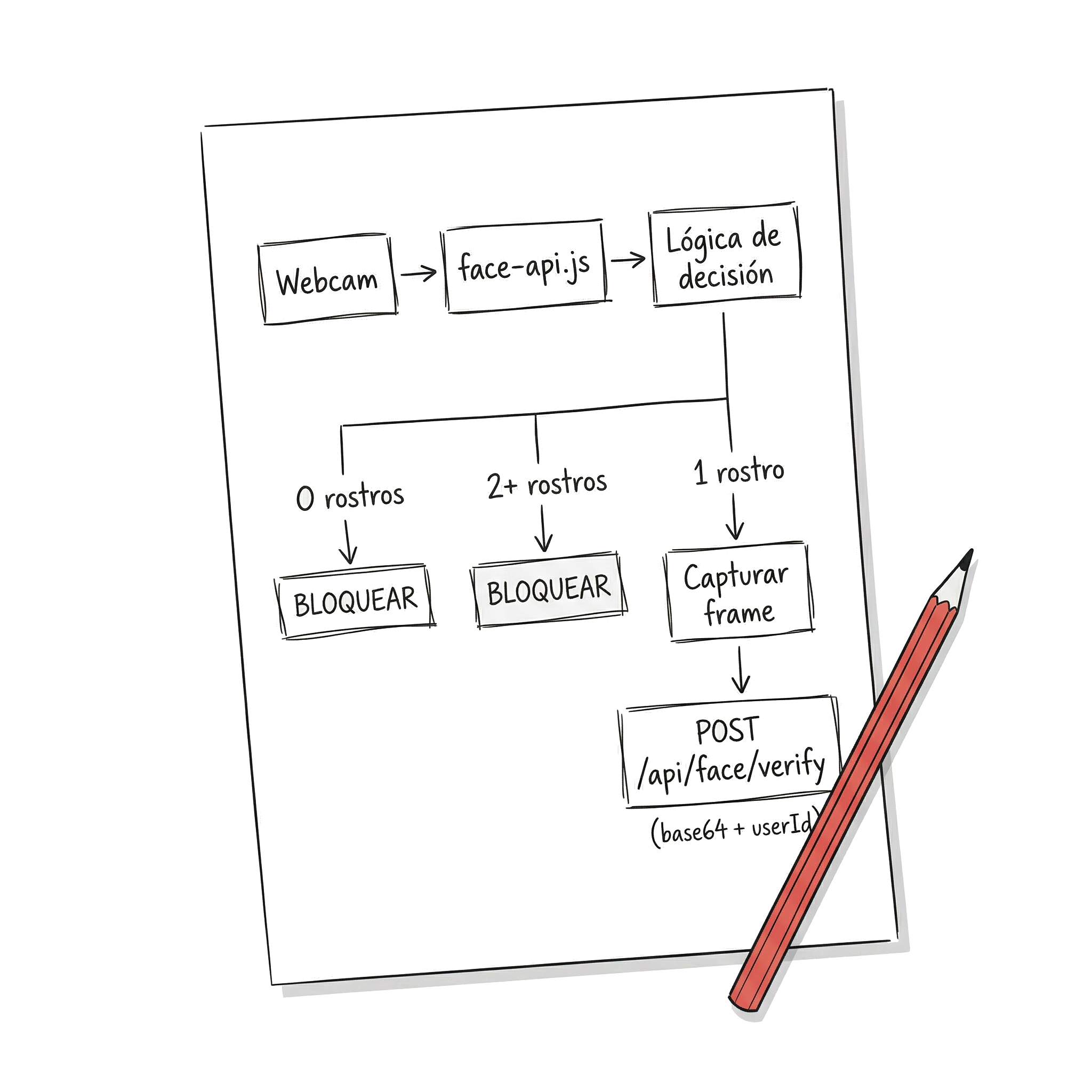
Una sola librería no resolvía el problema completo. Necesitábamos dos capacidades distintas: detectar que hay rostros frente a la cámara (¿cuántos?, ¿dónde?) y reconocer si el rostro detectado pertenece al usuario autorizado. La solución fue separar estas responsabilidades entre frontend y backend.
En el frontend, usamos face-api.js dentro de la aplicación React. Esta librería, construida sobre TensorFlow.js, ejecuta modelos de detección facial directamente en el navegador, y eso era clave para nuestro caso. Al estar migrando de una app mobile nativa a una app híbrida con React, necesitábamos una solución que corriera con el mismo código tanto en el browser de escritorio como en el webview de mobile. face-api.js, al ser 100% JavaScript ejecutándose sobre el contexto del navegador, cumplía exactamente ese requisito sin necesidad de bridges nativos ni código específico por plataforma. Su trabajo era simple pero crítico: acceder a la webcam, detectar rostros en cada frame, y cuando las condiciones cambiaban (un rostro nuevo aparecía, el usuario desaparecía, múltiples rostros simultáneos), capturar la imagen y enviarla al backend.
En el backend, construimos una API propia que integraba Luxand FaceSDK, la versión on-premise, no el servicio cloud. Luxand se encargaba del reconocimiento real: comparar la imagen recibida contra el template biométrico del usuario autenticado y responder con un nivel de confianza.
¿Por qué no usar Luxand Cloud? Costos. Estábamos construyendo un MVP, y una solución cloud con llamadas continuas a una API de reconocimiento facial habría sido prohibitivamente cara. Cada ciclo de verificación generaba una llamada al backend, y con monitoreo continuo, eso significaba decenas de llamadas por minuto por usuario. Con FaceSDK on-premise, el costo era una licencia fija, no un gasto variable que escala con el uso.
¿Por qué no hacer todo el reconocimiento en el navegador? Porque face-api.js, si bien puede hacer reconocimiento básico, no alcanzaba la precisión que necesitábamos para control de acceso real. Sus modelos son ligeros, diseñados para correr en el browser, pero eso implica trade-offs en accuracy. Luxand, con modelos más pesados corriendo en el servidor, ofrecía la precisión que un sistema de seguridad exige.
face-api.js en el frontend: detección continua en React
Integrar face-api.js en React tiene sus particularidades. No es un componente que renderizas y listo, es un sistema que necesita acceso a la webcam, carga modelos de machine learning, y ejecuta inferencia en un loop continuo. Todo eso debe convivir con el ciclo de vida de React sin provocar memory leaks ni degradar el rendimiento.
Carga de modelos
Lo primero es cargar los modelos de detección. face-api.js ofrece varios, SSD MobileNet, Tiny Face Detector, con diferentes balances entre precisión y velocidad. Para detección continua, Tiny Face Detector era la opción correcta: más rápido, suficiente para saber “hay un rostro aquí”, y deja que Luxand se encargue de la precisión en el reconocimiento.
Los modelos se servían como archivos estáticos desde la misma aplicación. Pesan entre 5 y 10 MB dependiendo de cuáles cargues, y la primera carga puede tomar unos segundos, algo que hay que manejar con un estado de loading en la UI.
Acceso a la webcam y loop de detección
El componente que encapsula la webcam y el loop de detección usa la API getUserMedia del navegador para obtener el stream de video, y ejecuta detectAllFaces de face-api.js en un intervalo regular para contar los rostros visibles en cada frame.
Algunas decisiones de diseño que vale la pena destacar. El elemento de video se oculta, el usuario no necesita ver su propia webcam, el componente corre en background mientras los documentos están visibles. El intervalo de detección lo fijamos en 500ms: un balance consciente entre responsividad y rendimiento. Más rápido consume CPU sin mejorar significativamente la seguridad; más lento deja una ventana donde alguien podría ver el documento antes del bloqueo. Y el cleanup al desmontar el componente es crítico, sin liberar el stream de la webcam y limpiar el intervalo, una SPA con navegación genera memory leaks severos.
Cuándo enviar al backend
No enviábamos cada frame al backend, eso sería inviable. La lógica estaba basada en cambios de estado: si no se detectaba ningún rostro, la pantalla se bloqueaba de inmediato sin consultar al servidor. Si se detectaban dos o más rostros, también se bloqueaba instantáneamente, no necesitaba ir al backend. Si hay más de una persona mirando, bloquear. Punto. Solo cuando se detectaba exactamente un rostro y la pantalla estaba bloqueada, el sistema capturaba el frame y lo enviaba al backend para verificar si correspondía al usuario autorizado. Si la respuesta era positiva, se desbloqueaba; si no, se mantenía el bloqueo.
Luxand FaceSDK en el backend: verificación de identidad
El backend recibía la imagen capturada y la comparaba contra el template biométrico del usuario que había iniciado sesión. El flujo tenía dos fases:
Enrollment (registro inicial): Cuando el usuario configuraba el reconocimiento facial por primera vez, la app capturaba varias imágenes desde diferentes ángulos y las enviaba al backend. Luxand generaba un template biométrico, una representación matemática del rostro, que se almacenaba asociado al usuario.
Verificación continua: Cada vez que el frontend enviaba un frame para validar, el backend extraía el template del frame recibido y lo comparaba contra el template almacenado del usuario. Luxand devolvía un score de similitud, y si superaba un umbral definido, confirmaba la identidad.
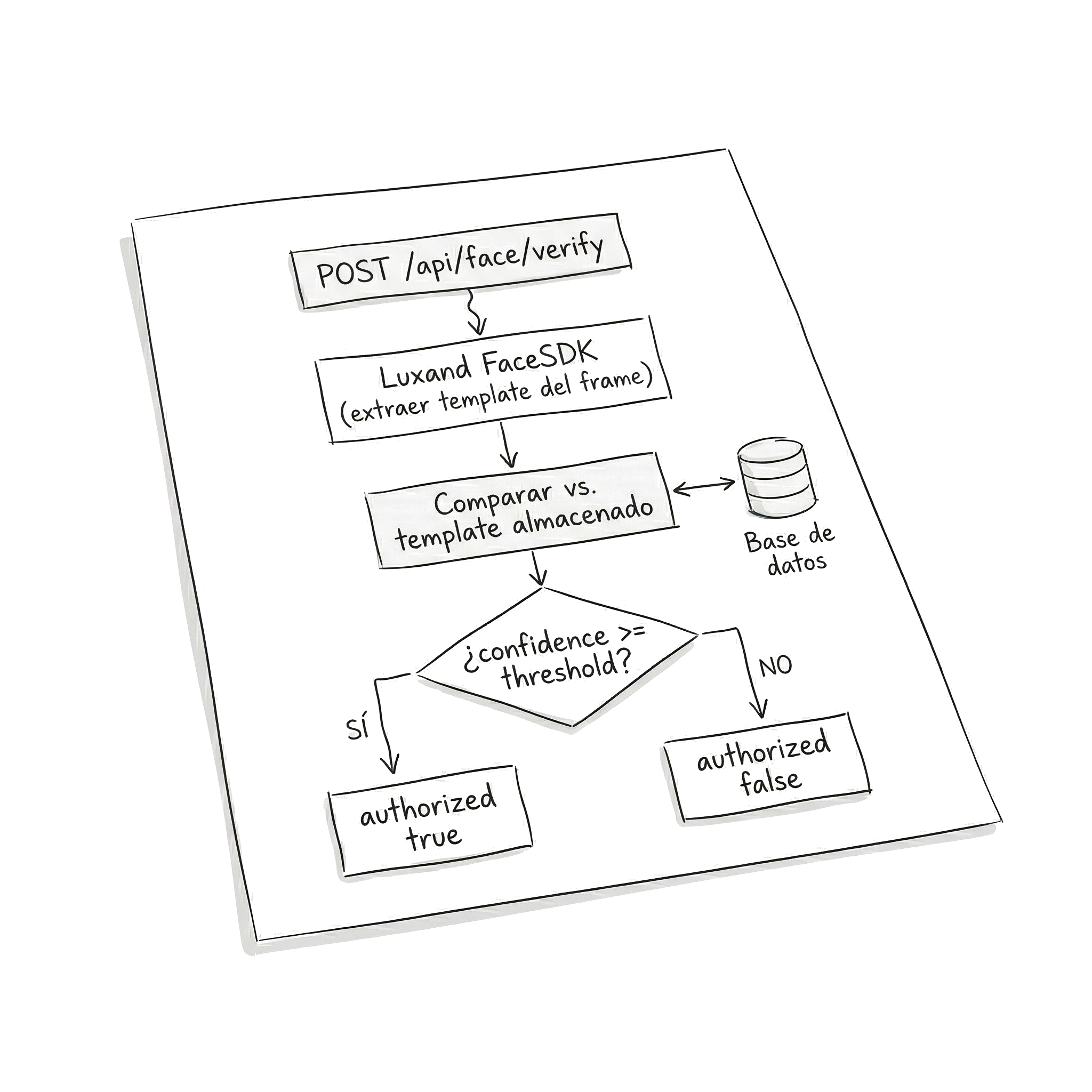
La API exponía un endpoint de verificación que recibía la imagen en base64 junto con el ID del usuario, y respondía con un booleano de autorización y el nivel de confianza del match.
El umbral de confianza fue uno de los parámetros que más ajustamos durante desarrollo. Demasiado alto y el sistema bloqueaba al usuario legítimo con frecuencia (cambios de iluminación, ángulo ligeramente diferente). Demasiado bajo y el sistema era permisivo con rostros similares.
Lo que funcionó y lo que no
Funcionó bien:
La separación frontend/backend demostró ser la decisión correcta. face-api.js era suficientemente rápido para detección continua, el Tiny Face Detector corría sin problemas visibles en máquinas modernas, y la lógica de “bloquear inmediatamente si hay múltiples rostros” no necesitaba precisión de reconocimiento, solo detección.
El bloqueo/desbloqueo automático se sentía fluido cuando las condiciones eran buenas: iluminación adecuada, cámara frontal de calidad, usuario centrado en el frame.
No funcionó tan bien:
- Iluminación. En oficinas con luz trasera fuerte (ventanas detrás del usuario), la detección fallaba. face-api.js perdía el rostro, el sistema asumía que no había nadie, y bloqueaba la pantalla aunque el usuario estuviera ahí. Frustrante.
- Cámaras de baja calidad. Webcams integradas en laptops económicas producían imágenes ruidosas. La detección funcionaba, pero la verificación en el backend bajaba su score de confianza, generando falsos negativos.
- El usuario se aleja del frame. Si el usuario se reclinaba en su silla o giraba la cabeza para hablar con alguien, el sistema podía perder la detección o bajar la confianza. Técnicamente correcto_, si no estás mirando la pantalla, quizás debería bloquearse, _pero en la práctica generaba interrupciones constantes.
- Peso de los modelos. Los archivos de face-api.js suman varios MB. En la primera carga, el usuario tenía que esperar la descarga y parsing de los modelos antes de que la detección comenzara. Implementamos caching con service workers, pero la carga inicial seguía siendo perceptible.
Privacidad y regulación: la ironía del caso
Hay algo irónico en usar reconocimiento facial para proteger la privacidad de documentos. Estás procesando datos biométricos, la categoría más sensible bajo la mayoría de marcos regulatorios, para proteger la confidencialidad de otros datos.
Cuando construimos esto en 2023, el MVP estaba enfocado en Estados Unidos. En ese momento, el panorama regulatorio ya era complejo, pero desde entonces se ha intensificado significativamente. Illinois BIPA (Biometric Information Privacy Act) sigue siendo la ley de privacidad biométrica más estricta del país: exige consentimiento escrito antes de recolectar identificadores biométricos, políticas de retención publicadas, y otorga a los individuos el derecho de demandar directamente, algo que ha generado litigios multimillonarios. Facebook pagó 650 millones de dólares por violar BIPA con su sistema de etiquetado facial, y Meta pagó 1.4 mil millones a Texas en 2024 por violaciones similares bajo la ley texana (CUBI).
Hoy, más de 20 estados tienen leyes de privacidad que clasifican datos biométricos como “sensibles” y requieren alguna forma de consentimiento. Colorado, por ejemplo, endureció sus requisitos desde julio de 2025, exigiendo consentimiento escrito informado y políticas de retención documentadas. Y la tendencia es clara: se espera que más estados aprueben legislación similar en los próximos años.
¿Qué significa esto para una aplicación como la que construimos? Si tu producto va a operar en Illinois, Texas, o cualquier estado con legislación biométrica activa, necesitas como mínimo: consentimiento explícito e informado del usuario antes de capturar datos faciales, una política pública de retención y destrucción de templates biométricos, y almacenamiento seguro de toda la información biométrica.
La arquitectura que elegimos detección en el cliente, sin enviar video continuo a servidores de terceros, resultó ser una ventaja desde la perspectiva de compliance, aunque no la diseñamos con esa intención. Los frames solo se enviaban a nuestro propio backend cuando era necesario verificar identidad, y los templates biométricos nunca salían de nuestra infraestructura. Si hubiéramos usado un servicio cloud de terceros, cada frame habría viajado a servidores externos, complicando significativamente el cumplimiento regulatorio en estados como Illinois, donde la cadena de custodia de los datos biométricos importa.
Qué elegiría hoy (2026)
Si tuviera que rediseñar esta arquitectura hoy, cambiaría el frontend. face-api.js está efectivamente abandonado, el repositorio original no ha recibido actualizaciones significativas desde 2020, y las issues se acumulan sin respuesta. Hay forks mantenidos por la comunidad, pero depender de un proyecto sin mantenimiento activo para un componente de seguridad no es aceptable.
MediaPipe de Google sería mi elección para el frontend. Disponible como paquete NPM (@mediapipe/tasks-vision), ofrece detección facial y landmarks con modelos BlazeFace optimizados para inferencia en el dispositivo. Su ventaja clave: es mantenido activamente por Google, soporta inferencia vía WebAssembly con delegación a GPU, y su API está diseñada para procesamiento en tiempo real, exactamente lo que necesitamos para monitoreo continuo. La integración con React seguiría el mismo patrón arquitectónico: un componente que encapsula la webcam y el loop de detección, pero usando FaceDetector y FilesetResolver de MediaPipe en lugar de face-api.js.
En el backend, Luxand FaceSDK sigue siendo una opción sólida, la versión 8.3 lanzada en 2025 incluye mejoras para WebAssembly y wrappers multiplataforma. Pero hoy también evaluaría si MediaPipe Face Landmarker, combinado con un modelo de embeddings faciales corriendo en el servidor, podría reemplazar a Luxand y eliminar la dependencia de una licencia comercial. La respuesta depende de los requisitos de precisión, para un MVP, probablemente sí; para un sistema donde la seguridad es crítica, Luxand o una solución similar con benchmarks publicados sigue siendo la apuesta más segura.
Mis Conclusiones
El reconocimiento facial en aplicaciones web no es solo un problema de machine learning, es un problema de arquitectura, rendimiento, UX y regulación.
Separar detección de reconocimiento entre frontend y backend fue la decisión más acertada del proyecto. Permitió usar herramientas ligeras donde la velocidad importaba (el navegador) y herramientas precisas donde la accuracy importaba (el servidor), sin acoplar ambas responsabilidades.
El monitoreo continuo es más difícil que la autenticación puntual. Un login facial ocurre una vez, condiciones controladas, el usuario coopera, tolerancia a un par de segundos de latencia. El monitoreo continuo debe funcionar todo el tiempo, con variaciones de luz, ángulo, y atención del usuario. Los falsos negativos son más destructivos que los falsos positivos, porque bloquean al usuario legítimo repetidamente.
La regulación ya no es un “después vemos”. En 2023 podíamos construir primero y preocuparnos por compliance después. En 2026, con más de 20 estados en USA con legislación de privacidad biométrica activa o en camino, y litigios multimillonarios como precedente, la arquitectura de privacidad debe diseñarse desde el día uno.
Para equipos construyendo MVPs: la combinación de detección en el cliente + verificación en un backend propio sigue siendo el patrón más pragmático. Te da control sobre costos, privacidad, y rendimiento. Solo asegúrate de elegir herramientas mantenidas activamente, face-api.js ya no lo está, y construir sobre proyectos abandonados es deuda técnica desde el primer commit.
Referencias
- face-api.js — JavaScript API for Face Detection and Face Recognition in the Browser and Node.js with TensorFlow.js.
- @vladmandic/face-api — Fork mantenido de face-api.js con compatibilidad para versiones recientes de TensorFlow.js.
- Luxand FaceSDK — SDK comercial de reconocimiento facial on-premise para múltiples plataformas.
- MediaPipe Face Detection (Google) — Detección facial y landmarks para aplicaciones web con inferencia on-device.